豆瓣电影信息爬取的实现
python爬虫:实现豆瓣电影Top250信息的爬取
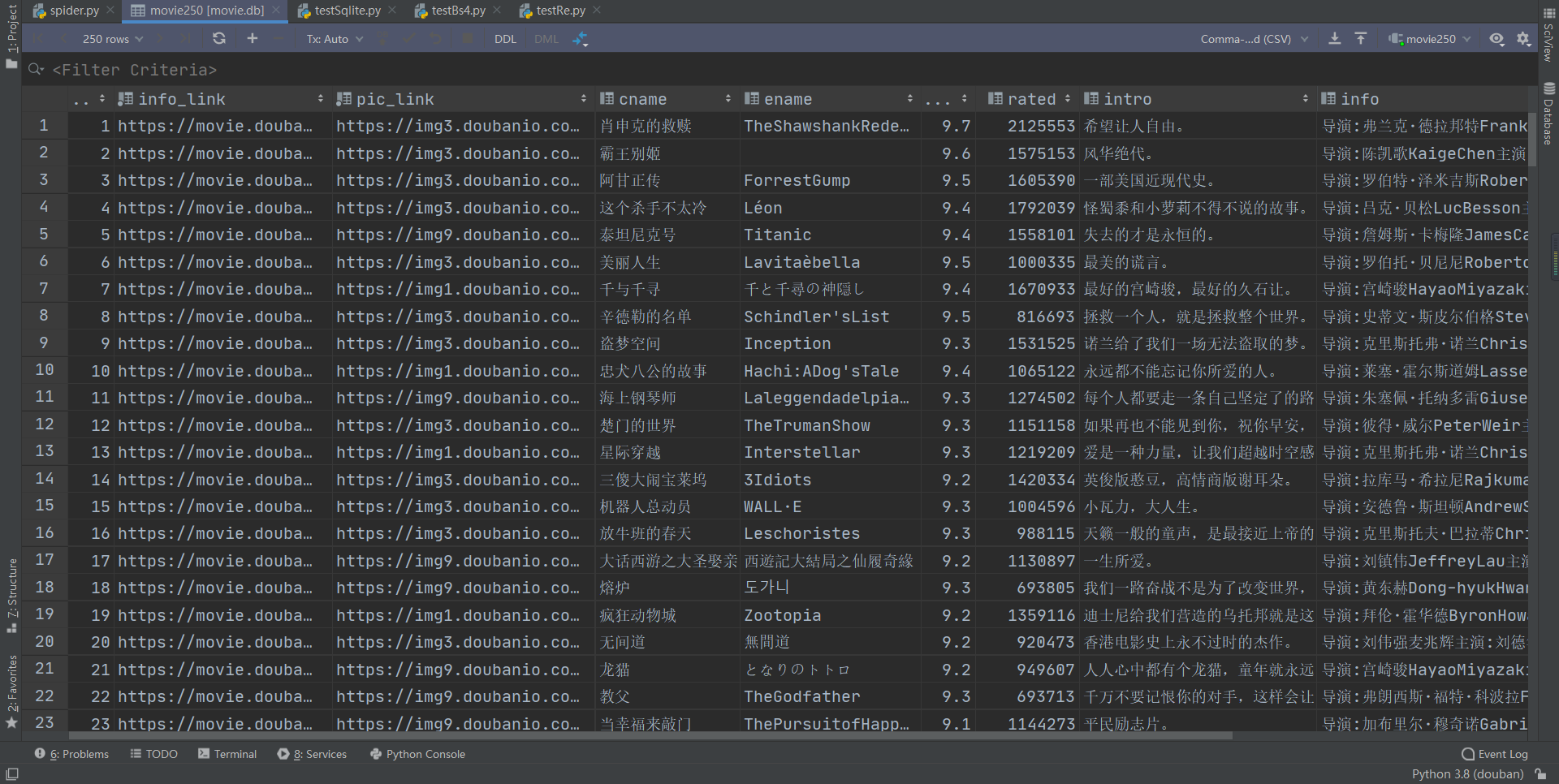
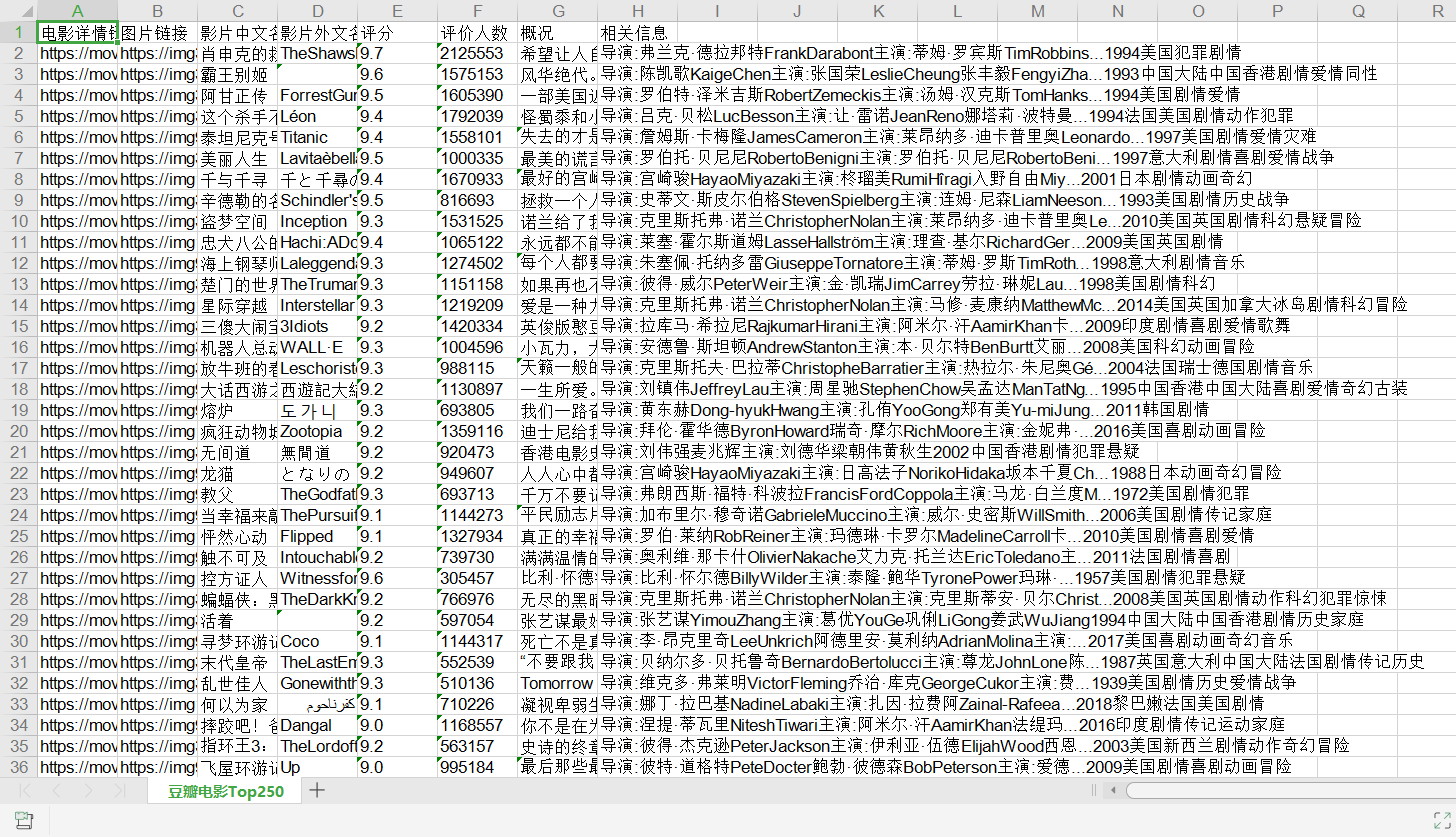
导语:疫情在家学习python,琢磨着写一个爬虫程序,实现豆瓣网站的信息爬取,并以Excel表格和SQLite数据库的方式保存,运行效果如下:
目录结构
Python爬虫 实现豆瓣电影Top250信息的爬取
运行python文件后生成数据库文件和表格文件
经过多次调试,已排除全部Bug,python文件具体代码如下:
1.头文件(自行修改)
1 | # -*- coding = utf-8 -*- |
2.导入相关类库
1 | from bs4 import BeautifulSoup # 网页解析,获取数据 |
3.制定正则表达式的规则
1 | # 1.获取影片超链接的规则 |
4.主程序功能模块
1 | # Step0.程序执行时 |
可以实现两种保存方式
5.爬取网页数据,逐一解析
tips:爬取网页时,由于是好几个网页,需要逐页解析,否则只会解析最后一页
1 | # Step1.爬取网页 |
6.获得豆瓣URL内容的方法
1 | # 得到指定一个URL的网页内容 |
7.保存数据到Excel
1 | # Step3.保存数据 |
8.保存数据到SQLite
1 | def saveData2DB(datalist,dbpath): |
9.主程序入口(必须写)
1 | # 程序入口(主方法) |
以上是python文件的全部代码,如有疑问,欢迎关注讨论
附:源码文件
本文标题:豆瓣电影信息爬取的实现
文章作者:Wyh0517
发布时间:2020-08-28
最后更新:2020-08-28
原始链接:https://wyh0517.github.io/2020/08/28/doubanTop250/
版权声明:作者拥有版权,如要转载请注明出处。@Wang-YH